This section contains technical and infrastructure documentation.
Background
Due to the number of systems and audiences involved, the current documentation plan is for the canonical documentation to be within the Github repository, using GitHub pages.
This provides a number of easy to use tools and systems to help keep standardised, versions and readable documentation.
Each repository will self document under the generic /docs/ folder/
Using Hugo module mounts the documentation for each repository will be integrated into the main documentation.
Documentation from each repository is effectively mounted in a virtual file tree where the documentation is then generated from. See the hugo docs for more info.
Documentation
Should be written in Markdown
Should be in a directory called docs in the top level of each repository. We have chosen this methodology as it allows for versioned documentation that matches the code base.
Either add themselves to the main site or ask an administrator to add them.
1 - Instruments
1.1 - RC MILabsU-CT
The microCT data needed to be transferred to the RDS before uploading from RDS to XNAT. Both XNAT and RDS will keep a copy of microCT
data at the current stage. If RDS storage researches its maximum capacity or budget in the future, the microCT data on RDS will be removed
periodically to save the space.
The microCT data can be categorized into three types: raw data, temporary data and reconstructed data.
The raw data is saved on the acquisition computer, and in the D drive of the reconstruction computer.
The temporary data is generated in the reconstruction process including the “corr” and “prev” folder of each scan and saved in the “ct-data”
folder. “corr” folder contains all the projection correction files, while “prev” folder contains the single slice preview image of reconstruction. “corr”
and “prev” folder will not be uploaded to the RDS and XNAT.
The reconstructed data contains the final images for CT reconstruction, and it is saved in the “Results” folder of each scan.
Data is uploaded from microCT to RDS daily at 7 p.m.
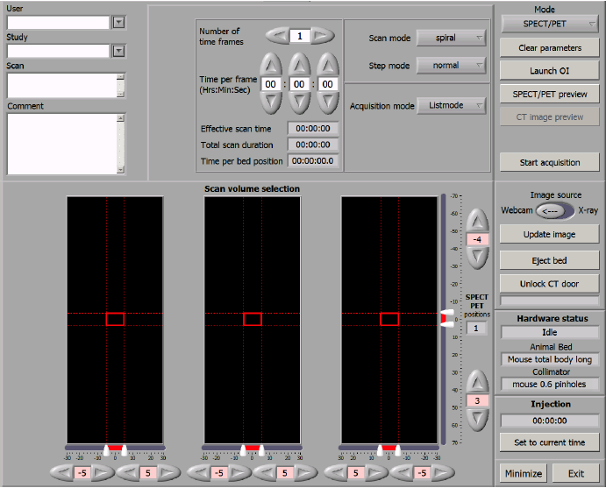
Acquisition control screen
The screenshot above is the acquisition control screen. The User field should always leave blank. The Study field should be filled with the XNAT
Project ID and Subject Name in XNAT, e.g. 123_SubjectName.
Project name can’t contain _, this symbol is used to separate the Project ID and Subject Name. Subject Name can contain any numbers of _.
The Scan name will become the Session name on XNAT.
One thing that you need to know when we want to create new ALB from EKS is service spec type can only support LoadBalancer and NodePort. It won’t support ClusterIP.
The Charts Repo has the service defined as ClusterIP so some changes need to be made to make this work. We will get to that later after we have created the ALB and policies.
In this document we create a Cluster called xnat in ap-southeast-2. Please update these details for your environment.
Create an IAM OIDC provider and associate with cluster:
kubectl get deployment -n kube-system aws-load-balancer-controller
You should see - READY 1/1 if it is installed properly
In order to apply this to the XNAT Charts Helm template update the charts/xnat/values.yaml file to remove the Nginx ingress parts and add the ALB ingress parts.
NB. Although you can specify ip or instance for the target-type, you need to specify ip or autoscaling won’t function correctly. This is because stickiness isn’t honoured for target-type instance so you have the known issue where XNAT database thinks you are logged in but instance / pod knows you are not and then it logs you out again.
For more ALB annotations / options, please see article at the bottom of the page.
As pointed out ClusterIP as service type does not work with ALB. So you will have to make some further changes to charts/xnat/charts/xnat-web/values.yaml:
Change:
service:type:ClusterIPport:80
to:
service:type:NodePortport:80
In xnat/charts/xnat-web/templates/service.yaml remove the line:
clusterIP:None
Then create the Helm chart with the usual command (after building dependencies - just follow README.md). If you are updating an existing xnat installation it will fail so you will need to create a new application.
helm upgrade xnat . -nxnat
It should now create a Target Group and Application Load Balancer in AWS EC2 Services. I had to make a further change to get this to work.
On the Target Group I had to change health check code from 200 to 302 to get a healthy instance because it redirects.
You can fix this by adding the following line to values file:
# Specify Health Checksalb.ingress.kubernetes.io/healthcheck-path:"/"alb.ingress.kubernetes.io/success-codes:"302"
Troubleshooting and make sure ALB is created:
watch kubectl -n kube-system get all
Find out controller name in pod. In this case - pod/aws-load-balancer-controller-98f66dcb8-zkz8k
Change the stickiness of the Load Balancer: It is important to set a stickiness time on the load balancer or you can get an issue where the Database thinks you have logged in but the pod you connect to knows you haven’t so you can’t login. Setting stickiness reasonably high – say 30 minutes, can get round this.
Add SSL encryption to your Application Load Balancer
Firstly, you need to add an SSL certificate to your ALB annotations. Kubernetes has a built in module: Cert Manager, to deal with cross clouds / infrastructure.
Finally, for this to successfully work you need to change the host path to allow any path or the Tomcat URL will be sent to a 404 by the Load Balancer. Put a wildcard in the paths to allow any eventual URL (starting with xnat.example.com in this case):
hosts:- host:xnat.example.compaths:["/*"]
Redirect HTTP to HTTPS:
This does not work on Kubernetes 1.19 or above as the “use-annotation” command does not work. There is seemingly no documentation on the required annotations to make this work.
Add the following annotation to your values file below the ports to listen on (see above):
You must then update the Rules section of ingress.yaml found within the releases/xnat/charts/xnat-web/templates directory to look like this when using Ingress apiVersion of networking.k8s.io/v1beta1 on Kuberbetes version prior to v1.22:
rules:{{- range .Values.ingress.hosts }}- host:{{.host | quote }}http:paths:{{- range .paths }}- path:{{.path }}backend:serviceName:{{$fullName }}servicePort:{{$svcPort }}{{- end }}{{- end }}
For Ingress apiVersion of networking.k8s.io/v1 on Kubernetes version >= v1.22:
rules:{{- range .Values.ingress.hosts }}- host:{{.host | quote }}http:paths:{{- range .paths }}backend:service:name:{{$fullName }}port:number:{{$svcPort }}{{- end }}{{- end }}
This will redirect HTTP to HTTPS on Kubernetes 1.18 and below.
One of the great things about Azure is the Azure Cli. Specify Bash and then you can run all commands through your web browser and all tools and kubectl / az commands are already installed and available without having to create them on your workstation or spin up a VM instance for the sole purpose of controlling the cluster.
You can do this via the console if you want. By Azure cli, see below. Create a resource group first.
Specify your Resource Group, cluster name (in our case xnat but please update if your Cluster is name differently), node count and VM instance size:
az aks create \
--resource-group <Resource Group Name> \
--name xnat \
--node-count 3\
--generate-ssh-keys \
--node-vm-size Standard_B2s \
--enable-managed-identity
Get AZ AKS credentials to run kubectl commands against your Cluster
az aks get-credentials --name xnat --resource-group <Resource Group Name>
Change to the correct directory and update dependencies. This will download and install the Postgresql Helm Chart. You don’t need to do this if you want to connect to an external Postgresql DB.
cd ~/charts/releases/xnat
helm dependency update
Create the namespace and install the chart, then watch it be created.
kubectl create namespace xnat
helm upgrade xnat ais/xnat --install -nxnat
watch kubectl -nxnat get all
It will complain that the Postgresql password is empty and needs updating.
Create an override values file (in this case values-aks.yaml but feel free to call it what you wish) and add the following inserting your own desired values:
It turns out that there is an issue with Storage classes that means that the volumes are not created automatically.
We need to make a small change to the storageClass configuration for the ReadWriteOnce volumes and create new external volumes for the ReadWriteMany ones.
Firstly, we create our own Azure files volumes for archive and prearchive and make a slight adjustment to the values configuration and apply as an override.
Follow this document for the details of how to do that:
Make a note of the Storage account name and key as you will need them.
Now repeat this process but update the Share name to xnat-xnat-web-prearchive and then again with xnat-xnat-web-build. Run this first and then repeat the rest of the commands:
AKS_PERS_SHARE_NAME=xnat-xnat-web-prearchive
and then update Share name and repeat the process again:
AKS_PERS_SHARE_NAME=xnat-xnat-web-build
Create a Kubernetes Secret
In order to mount the volumes, you need to create a secret. As we have created our Helm chart in the xnat namespace, we need to make sure that is added into the following command (not in the original Microsoft guide):
First, find out the resource name of the AKS Cluster:
az aks show --resource-group <your resource group> --name <your cluster name> --query nodeResourceGroup -o tsv
This will create the output for your next command.
az network public-ip create --resource-group <output from previous command> --name <a name for your public IP> --sku Standard --allocation-method static --query publicIp.ipAddress -o tsv
Point your FQDN to the public IP address you created
For the Letsencrypt certificate issuer to work it needs to be based on a working FQDN (fully qualified domain name), so in whatever DNS manager you use, create a new A record and point your xnat FQDN (xnat.example.com for example) to the IP address you just created.
You can find a write up of these commands and what they do in the Microsoft article.
Create a cluster-issuer.yaml to issue the Letsencrypt certificates
apiVersion:cert-manager.io/v1alpha2kind:ClusterIssuermetadata:name:letsencrypt-prodspec:acme:server:https://acme-v02.api.letsencrypt.org/directoryemail:your@emailaddress.comprivateKeySecretRef:name:letsencrypt-prodsolvers:- http01:ingress:class:nginxpodTemplate:spec:nodeSelector:"kubernetes.io/os": linux
In our case, we want production Letsencrypt certificates hence letsencrypt-prod (mentioned twice here and in values-aks.yaml). If you are doing testing you can use letsencrypt-staging. See Microsoft article for more details. Please do not forget to use your email address here.
Apply the yaml file:
kubectl apply -f cluster-issuer.yaml -nxnat
NB. To allow large uploads via the Compressed uploader tool you need to specify a value in the Nginx annotations or you get an “413 Request Entity Too Large” error. This needs to go in annotations:
Change yourxnat.example.com to whatever you want your XNAT FQDN to be. If you are using Letsencrypt-staging, update the cert-manager.io annotation accordingly.
Now update your helm chart and you should now have a fully working Azure XNAT installation with HTTPS redirection enabled, working volumes and fully automated certificates with automatic renewal.
“A service mesh, like the open source project Istio, is a way to control how different parts of an application share data with one another. Unlike other systems for managing this communication, a service mesh is a dedicated infrastructure layer built right into an app. This visible infrastructure layer can document how well (or not) different parts of an app interact, so it becomes easier to optimize communication and avoid downtime as an app grows.”
OK so a service mesh helps secure our environment and the communication between different namespaces and apps in our cluster (or clusters).
Istio is one of the most popular Service Mesh software providers so we will deploy and configure this for our environment. OK so let’s get to work.
There are several different ways to install Istio - with the Istioctl Operator, Istioctl, even on Virtual machines, but we will install the Helm version as AIS uses a Helm deployment and it seems nice and neat. Following this guide to perform the helm install: https://istio.io/latest/docs/setup/install/helm/
For our installation we won’t be installing the Istio Ingress Gateway or Istio Egress Gateway controller for our AWS environment. This is because AWS Cluster Autoscaler requires Application Load Balancer type to be IP whereas the Ingress Gateway controller does not work with that target type - only target type: Instance. This catch 22 forces us to use only istio and istiod to perform the service mesh and keep our existing AWS ALB Ingress controller. The standard install of Istio is to create an Istio Ingress Gateway, point it to a virtual service and then that virtual service points to your actual service.
At this point you may need to redeploy your pods if there are no sidecars present. When Istio is properly deployed, instead of xnat pods saying 1/1 they will say 2/2 - example:
kubectl get -nxnat all
NAME READY STATUS RESTARTS AGE
pod/xnat-postgresql-0 2/2 Running 0 160m
pod/xnat-xnat-web-0 2/2 Running 0 160m
Note about Cluster Austoscaler / Horizontal Pod Autoscaler as it applies to Istio
When using Kubernetes Horizontal Pod Autoscaling (HPA) to scale out pods automatically, you need to make adjustments for Istio. After enabling Istio for some deployments HPA wasn’t scaling as expected and in some cases not at all.
It turns out that HPA uses the sum of all CPU requests for a pod when determining using CPU metrics when to scale. By adding a istio-proxy sidecar to a pod we were changing the total amount of CPU & memory requests thereby effectively skewing the scale out point. So for example, if you have HPA configured to scale at 70% targetCPUUtilizationPercentage and your application requests 100m, you are scaling at 70m. When Istio comes into the picture, by default it requests 100m as well. So with istio-proxy injected now your scale out point is 140m ((100m + 100m) * 70% ) , which you may never reach. We have found that istio-proxy consumes about 10m in our environment. Even with an extra 10m being consumed by istio-proxy combined with the previous scale up trigger of 70m on the application container is well short (10m + 70m) of the new target of 140m
We solved this by calculating the correct scale out point and setting targetAverageValue to it.
kubectl get peerauthentication --all-namespaces
NAMESPACE NAME MODE AGE
default default STRICT 16h
istio-system default STRICT 28m
xnat default STRICT 16h
Now if we try to access our XNAT server we will get 502 Bad Gateway as the XNAT app can’t perform mTLS. Please substitute your XNAT URL below:
curl -X GET https://xnat.example.com
<html>
<head><title>502 Bad Gateway</title></head>
<body>
<center><h1>502 Bad Gateway</h1></center>
</body>
</html>
So next we want to allow traffic on port 8080 going to our xnat-xnat-web app only and apply mTLS for everything else, so amend istio-mtls.yaml:
You can also specify what commands we can run on our xnat-xnat-web app with Authorization policies and even specify via source from specific namespaces and even apps. This gives you the ability to completely lock down the environment. You can for instance allow a certain source POST access whilst another source only has GET and HEAD access.
Let’s create the following Authorization policy to allow all GET, HEAD, PUT, DELETE and OPTIONS commands to our xnat-web app called istio-auth-policy.yaml:
This completes fine. Now let’s try wtih a POST command not included in the authorization policy:
curl -X POST https://xnat.example.com
RBAC: access denied
So our policy is working correctly. However, as XNAT relies rather heavily on POST we will add it in to the policy and try again. Amend the yaml file to this:
This time it works. OK so we have a working Istio service mesh with correctly applied Mutual TLS and Authorization Policies.
This is only a tiny fraction of what Istio can do, so please go to their website for more information. You should try to lock down permissions further than specified above.
Kiali is a fantastic visualisation tool for Istio that helps you see at a glance what your namespaces are up to, if they are protected and allows you to add and update Istio configuration policies right through the web GUI. In combination with Prometheus and Jaeger, it allows to show traffic metrics, tracing and much more.
There are several ways of installing it with authentication (which for production workloads is a must). We are going to use the token method and using the AWS Classic Load Balancer to access.
It will then ask you for a Token for the service account to be able to login. Find it out with this command and then copy and paste and you now have a fully running kiali installation:
kubectl get secret -n istio-system \
$(kubectl get sa kiali-service-account -n istio-system -o jsonpath='{.secrets[0].name}')\
-o jsonpath='{.data.token}'| base64 -d
At this point I tried to set the AWS Elastic Load Balancer to use SSL and a proper certificate but after 4 hours of investigation it turns out that Kiali ingress requires "class_name" and AWS ELB doesn’t have one so that doesn’t work. Rather frustratingly I ended up manually updating the LoadBalancer lister details to be SSL over TCP and to specify the SSL Cipher policy and Certificate Manager. You should also point your FQDN to this Load Balancer to work with your custom certificate. No doubt an integration of Nginx and AWS ELB would fix this - Nginx being Kiali’s default ingress method.
Troubleshooting Istio
Use these commands for our XNAT environment to help debugging:
istioctl proxy-status
istioctl x describe pod xnat-xnat-web-0.xnat
istioctl proxy-config listeners xnat-xnat-web-0.xnat
istioctl x authz check xnat-xnat-web-0.xnat
kubectl logs pod/xnat-xnat-web-0 -c istio-proxy -nxnat
kubectl get peerauthentication --all-namespaces
kubectl get destinationrule --all-namespaces
3.1.4 - Using Kustomize as a Post renderer for the AIS XNAT Helm Chart
Kustomize
Using a Helm Chart is a pretty awesome way to deploy Kubernetes infrastructure in a neatly packaged, release versioned way. They can be updated from the upstream repo with a single line of code and for any customisations you want to add into the deployment you specify it in a values.yaml file.
Or at least that’s how it should work. As Helm is based on templates, sometimes a value is hardcoded into the template and you can’t change it in the values file. Your only option would have been to download the git repo that the Helm chart is based on, edit the template file in question and run it locally.
The problem with this approach is that when a new Helm Chart is released, you have to download the chart again and then apply all of your updates. This becomes cumbersome and negates the advantages of Helm.
Enter Kustomize. Kustomize can work in several ways but in this guide I will show you how to apply Kustomize as a post-renderer to update the template files to fit our environment. This allows you to continue to use the Helm Charts from the repo AND customise the Helm Chart templates to allow successful deployment.
Kustomize can be run as its own program using the kustomize build command or built into kubectl using kubectl kustomize. We are going to use the kustomize standalone binary.
This downloads to whatever directory you are in for whatever Operating System you are using. Copy it to /usr/local/bin to use it system wide:
sudo cp kustomize /usr/local/bin
How Kustomize works
When using Kustomize as a post renderer, Kustomize inputs all of the Helm Charts configuration data for a particular Chart in conjunction with the values file you specify with your cluster specific details and then amends the templates and applies them on the fly afterwards. This is why it is called a post renderer.
Let’s break this down.
1. Helm template
In order to extract all of the Helm chart information, you can use the helm template command. In the case of our XNAT/AIS Helm chart, to extract all of this data into a file called all.yaml (can be any filename) you would run this command:
helm template xnat ais/xnat > all.yaml
You now have the complete configuration of your Helm Chart including all template files in one file - all.yaml.
2. kustomization.yaml
The next step is a kustomization.yaml file. This file must be called kustomization.yaml or Kustomize doesn’t work. You create this and in it you specify your resources (inputs) - in our example, the resource will be all.yaml. The fantastic thing about Kustomize is you can add more resources in as well which combines with the Helm Chart to streamline deployment.
For instance, in my kustomization.yaml file I also specify a pv.yaml as another resource. This has information about creating Persistent Volumes for the XNAT deployment and creates the volumes with the deployment so I don’t have to apply this separately. You can do this for any resources you want to add to your deployment not included in the Helm chart. Example using all.yaml and pv.yaml in the kustomization.yaml file:
The second part of the Kustomization.yaml file is where you specify the files that patch the templates you need to change. You need to specify Filename and path, name of the original template, type and version. It should be pointed out there are a lot of other ways to use Kustomize - you can read about them in some of the included articles at the end of this guide.
In the above example, the file is service-patch.yaml and is in the same directory as kustomization.yaml, the name is xnat-xnat-web, the kind is Service and version is v1. Now lets look at the original service.yaml file to get a better idea. It is located in charts/releases/xnat/charts/xnat-web/templates/service.yaml:
apiVersion:v1kind:Servicemetadata:name:{{include "xnat-web.fullname" . }}labels:{{- include "xnat-web.labels" . | nindent 4 }}spec:type:{{.Values.service.type }}#clusterIP: Noneports:- port:{{.Values.service.port }}targetPort:8080protocol:TCPname:httpselector:{{- include "xnat-web.selectorLabels" . | nindent 4 }}sessionAffinity:"ClientIP"{{- if .Values.dicom_scp.recievers }}---apiVersion:v1kind:Servicemetadata:name:{{include "xnat-web.fullname" . }}-dicom-scplabels:{{- include "xnat-web.labels" . | nindent 4 }}{{- with .Values.dicom_scp.annotations }}annotations:{{- toYaml . | nindent 4 }}{{- end }}spec:type:{{.Values.dicom_scp.serviceType | quote }}ports:{{- $serviceType := .Values.dicom_scp.serviceType }}{{- range .Values.dicom_scp.recievers }}- port:{{.port }}targetPort:{{.port }}{{- if and (eq $serviceType "NodePort") .nodePort }}nodePort:{{.nodePort }}{{- end }}{{- if and (eq $serviceType "LoadBalancer") .loadBalancerIP }}loadBalancerIP:{{.loadBalancerIP }}{{- end }}{{- end }}selector:{{- include "xnat-web.selectorLabels" . | nindent 4 }}sessionAffinity:"ClientIP"{{- end }}
3. The Patch file
OK, so let’s have a look at our patch file and see what it is actually doing.
- op:removepath:"/spec/sessionAffinity"
Pretty simple really. - op: remove just removes whatever we tell it to in our service.yaml file. If we look through our file, we find spec and then under that we find sessionAffinity and then remove that. In this case if we remove all the other code to simplify things you get this:
spec:sessionAffinity:"ClientIP"
As sessionAffinity is under spec by indentation it will remove the line:
sessionAffinity:"ClientIP"
In this particular case my AWS Cluster needs Service Type to be NodePort so this particular line causes the XNAT deployment to fail, hence the requirement to remove it. OK so far so good. You can also use add and replace operations so let’s try an add command example as that is slightly more complicated.
Add and Replace commands example
OK continuing with our AWS NodePort example we will add a redirect from port 80 to 443 in the Ingress and replace the existing entry. In order to do that we need to add a second host path to the charts/releases/xnat/charts/xnat-web/templates/ingress.yaml. Lets look at the original file:
{{- if .Values.ingress.enabled -}}{{- $fullName := include "xnat-web.fullname" . -}}{{- $svcPort := .Values.service.port -}}apiVersion:networking.k8s.io/v1beta1{{- end }}kind:Ingressmetadata:name:{{$fullName }}labels:{{- include "xnat-web.labels" . | nindent 4 }}{{- with .Values.ingress.annotations }}annotations:{{- toYaml . | nindent 4 }}{{- end }}spec:{{- if .Values.ingress.tls }}tls:{{- range .Values.ingress.tls }}- hosts:{{- range .hosts }}- {{. | quote }}{{- end }}secretName:{{.secretName }}{{- end }}{{- end }}rules:{{- range .Values.ingress.hosts }}- host:{{.host | quote }}http:paths:{{- range .paths }}- path:{{.path }}backend:serviceName:{{$fullName }}servicePort:{{$svcPort }}{{- end }}{{- end }}{{- end }}
This is what we need in our values file to be reflected in the ingress.yaml file:
OK, so let’s break this down. The top command replaces this:
serviceName:{{$fullName }}
In this path:
rules:http:paths:backend:
With a hardcoded serviceName value:
serviceName:'ssl-redirect'
I removed the extra lines to show you only the relevant section.
The second command replaces:
servicePort:{{$svcPort }}
In the same path, with the hardcoded value:
servicePort:'use-annotation'
Now for the add command.
- op:addpath:/spec/rules/0/http/paths/-
This will add the values in normal yaml syntax here:
spec:rules:http:paths:-
NB. I have removed irrelevant lines to simplify the example. If there were already two sets of path directive, replacing or adding to the second one would require this path:
path:/spec/rules/1/http/paths/-
OK so the resultant transformation of the ingress.yaml file will change it to look like this:
This takes the contents of all.yaml and kustomizes it using the kustomization.yaml file with the resources and patches I have previously described. Finally, it deletes all.yaml. When you run kustomize build it will look for a file called kustomization.yaml to apply the transformations. As the kustomization.yaml file is in the same directory as hook.sh only the kustomize build command is needed, no further directive is required.
5. Deploy the Helm Chart with Kustomize post-renderer
OK to bring it all together and upgrade the XNAT AIS helm chart with your values file as values.yaml in the namespace xnat, run this command:
There are a lot of configuration options for Kustomize and this just touched on the basics. Kustomize is also really useful for creating dev, staging and production implementations using the same chart. See these articles:
The XNAT & POSTGRES service should be up and running fine. Linode Storage Class linode-block-storage-retain should have automatically
come in place & PVs will be auto created to be consumed by our mentioned PVCs.
6. Ingress Controller/Load balancer Installation
Install Ingress Controller and provision a Load balancer (Nodebalancer in Linode) by executing these commands
>NAME: ingress-nginx
LAST DEPLOYED: Mon Aug 2 11:51:32 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
The ingress-nginx controller has been installed.
It may take a few minutes for the LoadBalancer IP to be available.
7. Domain Mapping
Get the External IP address of the Loadbalancer by running the below command and assign it to any domain or subdomain.
Example:cloud.neura.edu.au is the subdomain for which the loadbalancer IP is assigned in my case.
Please replace it with your domain in this and all upcoming steps
kubectl --namespace default get services -o wide -w ingress-nginx-controller
8. HTTP Traffic Routing via Ingress
It is time to create a Ingress object that directs the traffic based on the host/domain to the already available XNAT service.
Get the XNAT service name by issuing the below command and choose the service name that says TYPE as ClusterIP
kubectl get svc -nxnat -l "app.kubernetes.io/name=xnat-web"
Example: xnat-deployment-xnat-web
Using the above service name, write an ingress object to route the external traffic based on the domain name.
After the creation of this Ingress object, make sure cloud.neura.edu.au is routed to the XNAT application over HTTP successfully.Let us delete the ingress object after checking because we will be creating another one with TLS to use HTTPS.
kubectl delete ingress xnat-ingress -nxnat
10. Install cert-manager for Secure Connection HTTPS
Verify that the corresponding cert-manager pods are now running.
kubectl get pods --namespace cert-manager
You should see a similar output:
>NAME READY STATUS RESTARTS AGE
cert-manager-579d48dff8-84nw9 1/1 Running 3 1m
cert-manager-cainjector-789955d9b7-jfskr 1/1 Running 3 1m
cert-manager-webhook-64869c4997-hnx6n 1/1 Running 0 1m
11. Creation of ClusterIssuer to Issue certificates
Create a manifest file named acme-issuer-prod.yaml that will be used to create a ClusterIssuer resource on your cluster. Ensure you replace user@example.com with your own email address.
The /docs/Deployment folder is a dump directory for any documentation related to deployment of the AIS released services. This includes, but is not limited to, deployment examples:
from different AIS sites
utilising alternate Cloud services or on-prem deployments
configuration snippets
Jekyll is used to render these documents and any MarkDown files with the appropriate FrontMatter tags will appear in the Deployment drop-down menu item.
Getting started with an XNAT deployment step-by-step
This quick start guide will follow a progression starting from the most basic single instance XNAT deployment
up to a full XNAT service.
Please be aware that this is a guide and not considered a production ready service.
Prerequisites
a Kubernetes service. You can use Microk8s on your workstation if you do not have access to a cloud service.
Kubectl client installed and configured to access your Kubernetes service
Helm client installed
Microk8s minimal enabled plugins
microk8s enable dns
microk8s enable rbac
microk8s enable storage
What settings can be modified and where?
helm show values ais/xnat
Just XNAT
Create minimal helm values file ~/values.yaml.
XNAT requires a minimum of 4GiB of RAM and 4x vCPUs. If your system is close to or smaller than these resources
then XNAT could take several minutes to start. If so, it is recommended that you add something similar to the settings
bellow for your deployment.
As an example, a test conducted (27/5/2025) on a VM with 4GiB of RAM and 4x vCPUs, took just over 6.5 minutes
for XNAT to start and present a healthy system.
---xnat-web:resources:requests:memory:500Milimits:memory:3000Mi# 1 GiB lower than your system.probes:startup:failureThreshold:120# Disables the process watchdog for an extended period of time.
# Setup AIS Helm chartshelm repo add ais https://australian-imaging-service.github.io/charts
helm repo update
# Deploy minimal XNAT# This command is also used to action changes to the `values.yaml` filehelm upgrade xnat ais/xnat --install --values ~/values.yaml --namespace xnat-demo --create-namespace
# From another terminal you can run the following commnad to watch deployment of resourceswatch kubectl -nxnat-demo get all,pv,pvc
# From another terminal run the following command and# access XNAT web UI from a browser with address `http://localhost:8080`kubectl -nxnat-demo port-forward service/xnat-xnat-web-0 8080:80
Things to watch out for.
This deployment will utilise the default storage class configured for your Kubernetes service.
If there is no storage class set as default this deployment will not have any persistent volume(s)
provisioned and will not complete.
Out of scope for this document is how to manually create a Persistent Volume and bind to a Persistent Volume Claim.
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
microk8s-hostpath (default) microk8s.io/hostpath Delete Immediate false 145d
You can see that Microk8s has a default storage class. However if this was not the case or another storage class was to be used the following would need to be added to your values.yaml file.
---global:storageClass:"microk8s-hostpath"
You should be seeing something similar to the following
$ kubectl -nxnat-demo get all,pvc
NAME READY STATUS RESTARTS AGE
pod/xnat-postgresql-0 1/1 Running 30 27d
pod/xnat-xnat-web-0 1/1 Running 30 27d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/xnat-xnat-web-headless ClusterIP None <none> 80/TCP 27d
service/xnat-postgresql-headless ClusterIP None <none> 5432/TCP 27d
service/xnat-postgresql ClusterIP 10.152.183.17 <none> 5432/TCP 27d
service/xnat-xnat-web ClusterIP 10.152.183.193 <none> 80/TCP 27d
service/xnat-xnat-web-dicom-scp NodePort 10.152.183.187 <none> 8104:31002/TCP 27d
NAME READY AGE
statefulset.apps/xnat-postgresql 1/1 27d
statefulset.apps/xnat-xnat-web 1/1 27d
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/xnat-xnat-web-archive Bound pvc-81a7308c-fb64-4acd-9a04-f54dbc6e1e0b 1Ti RWX microk8s-hostpath 27d
persistentvolumeclaim/xnat-xnat-web-prearchive Bound pvc-357f45aa-79af-4958-a3fe-ec3714e6db13 1Ti RWX microk8s-hostpath 27d
persistentvolumeclaim/data-xnat-postgresql-0 Bound pvc-45d917d7-8660-4183-92cb-0e07c59d9fa7 8Gi RWO microk8s-hostpath 27d
persistentvolumeclaim/cache-xnat-xnat-web-0 Bound pvc-f868215d-0962-4e99-95f5-0cf09440525f 10Gi RWO microk8s-hostpath 27d
Tool for running local Kubernetes clusters using Docker container “nodes”
Testing chart functionality
3.2.2 - Development workstation with Multipass on MacOS
Requirements
An enabled hypervisor, either HyperKit or VirtualBox. HyperKit is the default hypervisor backend on MacOS Yosemite or later installed on a 2010 or newer Mac.
Administrative access on Mac.
Download, install and setup Multipass
There are two ways to install Multipass on MacOS: brew or the installer. Using brew is the simplest:
$ brew install --cask multipass
Check Multipass version which you are running:
$ multipass version
Start a Multipass VM, then install Microk8s
Brew is the easiest way to install Microk8s, but it is not so easy to install an older version. At the time of writing, Microk8s latest version v1.20 seems to have problem for Ingress to attach an external IP (127.0.0.1 on Microk8s vm). We recommend manual installation.
sudo snap install microk8s --classic
microk8s enable dns fluentd ingress metrics-server prometheus rbac registry storage
# Install and configure the kubectl clientsudo snap install kubectl --classic
# Start running more than one cluster and you will be glad you did these stepsmicrok8s config |sed 's/\(user\|name\): admin/\1: microk8s-admin/' >${HOME}/.kube/microk8s.config
# On Mac, use below to set up the admin user# microk8s config |sed 's/\([user\|name]\): admin/\1: microk8s-admin/' >${HOME}/.kube/microk8s.configcat >>${HOME}/.profile <<'EOT'
DIR="${HOME}/.kube"
if [ -d "${DIR}" ]; then
KUBECONFIG="$(/usr/bin/find $DIR \( -name 'config' -o -name '*.config' \) \( -type f -o -type l \) -print0 | tr '\0' ':')"
KUBECONFIG="${KUBECONFIG%:}"
export KUBECONFIG
fi
EOT# logout or run the above code in your current shell to set the KUBECONFIG environment variablekubectl config use-context microk8s
If you have an issue with the operation of microk8s microk8s inspect command is you best friend.
microk8s notes
To enable a Load Balancer microk8s comes with metalLB and configures Layer2 mode settings by default. You will be asked for an IPv4 block of addresses, ensure that the address block is in the same Layer 2 as your host, unused and reserved for this purpose (you may need to alter your DHCP service). When you are ready perform the following:
$ microk8s enable metallb
microk8s does not support IPv6 at this time!
3.2.5 - Windows 10: Multipass
Development workstation with Multipass on Windows 10
Requirements:
An enabled Hypervisor, either Hyper-V (recommended) or VirtualBox (introduces certain networking issues, if you are using VirtualBox on Windows 10 then use the VirtualBox UI directly or another package such as Vagrant)
Administrative access to Windows 10 workstation. This is required for:
Enabling Hyper-V if not already configured, or installing Oracle VirtualBox
Installing Multipass
Altering the local DNS override file c:\Windows\System32\drivers\etc\hosts
Windows PowerShell console as Administrator
Right click Windows PowerShell and select Run as Administrator, enter your Admin credentials. From the Administrator: Windows PowerShell console perform the following.
Open the DNS hosts file for editing.
Warning
Edit this file with care and ensure that you only append entries while leaving the original entries intact.
Also be aware that you have started Notepad as an Administrator allowing this application to be able to edit any file on your system. Close the editor and PowerShell console if you intend to leave your workstation!
From the Multipass website, verify that your Windows 10 workstation meets the minimum requirements and then download the Windows installation file.
Select Start button and then select Settings.
In Settings, select System > About or type about in the search box.
Under Windows specifications verify Edition and Version
Follow the installation instructions from the Multipass site selecting the preferred Hypervisor.
NB: The Environment variable that configure the search PATH to find the Multipass binaries will not be available until you logout and log back in.
Edit the workstations local DNS lookup/override file
This is required to direct your workstations browser and other clients to the development VM which runs your CTP and/or XNAT service.
For each service requiring a DNS entry you will need to add an entry into your hosts file. From your Notepad application opened as an Administrator you will need to enter the following.
So if your VM’s IP address is 192.168.11.93 and your service FQDN is xnat.cmca.dev.local add the following entry into C:\Windows\System32\drivers\etc\hosts file and save.
C:\Windows\System32\drivers\etc\hosts
192.168.11.93 xnat.cmca.dev.local
Launch Ubuntu 20.04 LTS (Focal) with AIS development tools
# add the required helm repositorieshelm repo add bitnami https://charts.bitnami.com/bitnami
# import the helm chart dependencies (e.g., PostgreSQL) from the xnat chart directory# ensure you have cloned the repo and changed to charts/xnat directory before running this commandhelm dependency update
# view the helm output without deployment from the xnat chart directoryhelm install --debug --dry-run xnat ais/xnat 2>&1|less
# create xnat namespace in kuberneteskubectl create ns xnat
# Deploy the AIS XNAT servicehelm upgrade xnat ais/xnat --install --values ./my-site-overrides.yaml --namespace xnat
# Watch the AIS goodnesswatch kubectl -nxnat get all
# watch the logs scroll bykubectl -nxnat logs xnat-xnat-web-0 -f
# find out what happened if pod does not startkubectl -nxnat get pod xnat-xnat-web-0 -o json
# view the persistent volumeskubectl -nxnat get pvc,pv
# view the content of a secretkubectl -nxnat get secret xnat-xnat-web -o go-template='{{ index .data "xnat-conf.properties" }}'| base64 -d
# tear it all downhelm delete xnat -nxnat
kubectl -nxnat delete pod,svc,pvc --all
kubectl delete namespace xnat
The /docs/_development folder is a dump directory for any documentation related to setup and practices of development related to the AIS released services.
Jekyll is used to render these documents and any MarkDown files with the appropriate FrontMatter tags will appear in the Development drop-down menu item.
3.3.1 - Integrating AAF with AIS Kubernetes XNAT Deployment
Applying for AAF Integration ClientId and Secret
AAF have several services they offer which authenticate users, for example, Rapid Connect.
We are interested in the AAF OIDC RP service.
Please contact AAF Support via email at support@aaf.net.au to apply for a ClientId and Secret.
They will ask you these questions:
The service’s redirect URL - a redirect URL based on an actual URL rather than IP address and must use HTTPS.
A descriptive name for the service.
The organisation name, which must be an AAF subscriber, of the service.
Indicate the service’s purpose - development/testing/production-ready.
Your Keybase account id to share the credentials securely.
For 1. This is extremely important and based on two options in the openid-provider.properties file:
siteUrl
preEstablishedRedirUri
We will use this example below (this is the correct syntax):
For 5. Just go to https://keybase.io/ and create an account to provide to AAF support so you can receive the ClientId and ClientSecret securely.
Installing the AAF Plugin in a working XNAT environment
There have been long standing issues with the QCIF plugin that have been resolved by the AIS Deployment team – namely unable to access any projects – see image below.
This issue occurred regardless of project access permissions. You would receive this error message trying to access your own project!
AIS Deployment team created a forked version of the plugin which fixes this issue. You can view it here:
To deploy to XNAT, navigate to the XNAT home/ plugins folder on your XNAT Application Server – normally /data/xnat/home/plugins and then download. Assuming Linux:
You now have xnat-openid-auth-plugin-all-1.0.2.jar in /data/xnat/home/plugins. You now need the configuration file which will be (assuming previous location for XNAT Home directory):
AAF ClientID and Secret – CASE SENSITIVE - openid.aaf.clientID for example would mean AAF plugin will not function
These are fake details but an example – no “ (quotation marks) required.
If the below is wrong the AAF logo will not appear on the login page and you won’t be able to login
openid.aaf.link=<p>To sign-in using your AAF credentials, please click on the button below.</p><p><a href="/openid-login?providerId=aaf"><img src="/images/aaf_service_223x54.png" /></a></p>
Flag that sets if we should be checking email domains
openid.aaf.shouldFilterEmailDomains=false
Domains below are allowed to login, only checked when shouldFilterEmailDomains is true
openid.aaf.allowedEmailDomains=example.com
Flag to force the user creation process, normally this should be set to true
openid.aaf.forceUserCreate=true
Flag to set the enabled property of new users, set to false to allow admins to manually enable users before allowing logins, set to true to allow access right away
openid.aaf.userAutoEnabled=false
Flag to set the verified property of new users – use in conjunction with auto.verified
If you create your openid-provider.properties file with the above information, tailored to your environment, along with the plugin: /data/xnat/home/plugins/xnat-openid-auth-plugin-all-1.0.2.jar
You should only need to restart Tomcat to enable login. This assumes you have a valid AAF organisation login.
Using AAF with the AIS Kubernetes Chart Deployment
The AIS Charts Helm template has all you need to setup a completely functional XNAT implementation in minutes, part of this is AAF integration.
Prerequisites:
• A functional HTTPS URL with valid SSL certificate for your Kubernetes cluster. See the top of this document for details to provide to AAF. • A ClientId and Secret provided by AAF. • A Load Balancer or way to connect externally to your Kubernetes using the functional URL with SSL certificate.
then edit the following file: charts/releases/xnat/charts/xnat-web/values.yaml
And update the following entries underneath openid:
NB> These entries DO require being placed within “”
preEstablishedRedirUri:"/openid-login"siteUrl:""#List of providers that appear on the login pageproviders:aaf:accessTokenUri:https://central.aaf.edu.au/providers/op/token#accessTokenUri: https://central.test.aaf.edu.au/providers/op/tokenuserAuthUri:https://central.aaf.edu.au/providers/op/authorize#userAuthUri: https://central.test.aaf.edu.au/providers/op/authorizeclientId:""clientSecret:""
Comment out the Test or Production providers depending on which environment your XNAT will reside in. To use the example configuration from the previous configuration, the completed entries will look like this:
preEstablishedRedirUri:"/openid-login"siteUrl:"https://xnat.example.com"#List of providers that appear on the login pageproviders:aaf:accessTokenUri:https://central.test.aaf.edu.au/providers/op/tokenuserAuthUri:https://central.test.aaf.edu.au/providers/op/authorizeclientId:"123jsdjd"clientSecret:"chahdkdfdhffkhf"
You can now deploy your Helm template by following the README here:
https://github.com/Australian-Imaging-Service/charts
In order for this to work, you will need to point your domain name and SSL certificate to the Kubernetes xnat-web pod, which is outside of the scope of this document.
Troubleshooting
Most of the above documentation should remove the need for troubleshooting but a few things to bear in mind.
All of the openid-provider.properties file and the values.yaml file mentioned above for either existing XNAT deployments are CASE SENSITIVE. The entries must match exactly AAF won’t work.
If you get a 400 error message when redirecting from XNAT to AAF like so:
The ClientId entry is wrong. This happened before when the properties file had ClientId like this:
openid.aaf.clientID
rather than:
openid.aaf.clientId
You can see client_id section is empty. This wrongly capitalised entry results in the clientId not be passed to the URL to redirect and a 400 error message.
Check the log files. The most useful log file for error messages is the Tomcat localhost logfile. On RHEL based systems, this can be found here (example logfile):
/var/log/tomcat7/localhost.2021-08-08.log
You can also check the XNAT logfiles, mostly here (depending on where XNAT Home is on your system):
/data/xnat/home/logs
3.3.2 - Autoscaling XNAT on Kubernetes with EKS
There are three types of autoscaling that Kubernetes offers:
Horizontal Pod Autoscaling Horizontal Pod Autoscaling (HPA) is a technology that scales up or down the number of replica pods for an application based on resource limits specified in a values file.
Vertical Pod Autoscaling Vertical Pod Autoscaling (VPA) increases or decreases the resources to each pod when it gets to a certain percentage to help you best deal with your resources.
After some testing this is legacy and HPA is preferred and also built into the Helm chart so we won’t be utilising this technology.
Cluster-autoscaling Cluster-autoscaling is where the Kubernetes cluster itself spins up or down new Nodes (think EC2 instances in this case) to handle capacity.
You can’t use HPA and VPA together so we will use HPA and Cluster-Autoscaling.
Prerequisites
Running Kubernetes Cluster and XNAT Helm Chart AIS Deployment
AWS Application Load Balancer (ALB) as an Ingress Controller with some specific annotations
Resources (requests and limits) need to specified in your values file
Metrics Server
Cluster-Autoscaler
You can find more information on applying ALB implementation for the AIS Helm Chart deployment in the ALB-Ingress-Controller document in this repo, so will not be covering that here, save to say there are some specific annotations that are required for autoscaling to work effectively.
Change the stickiness of the Load Balancer: It is important to set a stickiness time on the load balancer. This forces you to the same pod all the time and retains your session information.
Without stickiness, after logging in, the Database thinks you have logged but the Load Balancer can alternate which pod you go to. The session details are kept on each pod so the new pod thinks you aren’t logged in and keeps logging you out all the time. Setting stickiness time reasonably high – say 30 minutes, can get round this.
Change the Target type: Not sure why but if target-type is set to instance and not ip, it disregards the stickiness rules.
alb.ingress.kubernetes.io/target-type:ip
Resources (requests and limits) need to specified in your values file
In order for HPA and Cluster-autoscaling to work, you need to specify resources - requests and limits, in the AIS Helm chart values file, or it won’t know when to scale. This makes sense because how can you know when you are running out of resources to start scaling up if you don’t know what your resources are to start with?
In your values file add the following lines below the xnat-web section (please adjust the CPU and memory to fit with your environment):
From my research with HPA, I discovered a few important facts.
Horizontal Pod Autoscaler doesn’t care about limits, it bases autoscaling on requests. Requests are meant to be the minimum needed to safely run a pod and limits are the maximum. However, this is completely irrelevant for HPA as it ignores the limits altogether so I specify the same resources for requests and limits. See this issue for more details:
XNAT is extremely memory hungry, and any pod will use approximately 750MB of RAM without doing anything. This is important as when the requests are set below that, you will have a lot of pods scale up, then scale down and no consistency for the user experience. This will play havoc with user sessions and annoy everyone a lot. Applications - specifically XNAT Desktop can use a LOT of memory for large uploads (I have seen 12GB RAM used on an instance) so try and specify as much RAM as you can for the instances you have. In the example above I have specified 3000MB of RAM and 1 vCPU. The worker node instance has 4 vCPUs and 4GB. You would obviously use larger instances if you can. You will have to do some testing to work out the best Pod to Instance ratio for your environment.
Metrics Server
Download the latest Kubernetes Metrics server yaml file. We will need to edit it before applying the configuration or HPA won’t be able to see what resources are being used and none of this will work.
Congratulations - you now have an up and running Metrics server. You can read more about Metrics Server here:
https://github.com/kubernetes-sigs/metrics-server
Cluster-Autoscaler
There are quite a lot of ways to use the Cluster-autoscaler - single zone node clusters deployed in single availability zones (no AZ redundancy), single zone node clusters deployed in multiple Availability zones or single Cluster-autoscalers that deploy in multiple Availability Zones. In this example we will be deploying the autoscaler in multiple Availability Zones (AZ’s).
In order to do this, a change needs to be made to the StorageClass configuration used.
Delete whatever StorageClasses you have and then recreate them changing the VolumeBindingMode. At a minimum you will need to change the GP2 / EBS StorageClass VolumeBindingMode but if you are using a persistent volume for archive / prearchive, that will also need to be updated.
Relevant section: If you need to run a single ASG spanning multiple AZs and still need to use EBS volumes you may want to change the default VolumeBindingMode to WaitForFirstConsumer as described in the documentation here. Changing this setting “will delay the binding and provisioning of a PersistentVolume until a pod using the PersistentVolumeClaim is created.” This will allow a PVC to be created in the same AZ as a pod that consumes it.
If a pod is descheduled, deleted and recreated, or an instance where the pod was running is terminated then WaitForFirstConsumer won’t help because it only applies to the first pod that consumes a volume. When a pod reuses an existing EBS volume there is still a chance that the pod will be scheduled in an AZ where the EBS volume doesn’t exist.
You can refer to AWS documentation for how to install the EKS Cluster-autoscaler:
This is the relevant parts of my environment when running the get command:
k -nxnat get horizontalpodautoscaler.autoscaling/xnat-xnat-web
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
xnat-xnat-web StatefulSet/xnat-xnat-web 34%/80%, 0%/80% 21002 3h29m
As you can see 34% of memory is used and 0% CPU. Example of get command for pods - no restarts and running nicely.
k -nxnat get pods
NAME READY STATUS RESTARTS AGE
pod/xnat-xnat-web-0 1/1 Running 0 3h27m
pod/xnat-xnat-web-1 1/1 Running 0 3h23m
Troubleshooting
Check Metrics server is working (assuming in the xnat namespace) and see memory and CPU usage:
XNAT uses pipelines to perform various different processes - mostly converting image types to other image types (DICOM to NIFTI for example). In the past this was handled on the instance as part of the XNAT program, then as a docker server on the instance and finally, externally as an external docker server, either directly or using Docker swarm. XNAT utilises the Container service which is a plugin to perform docker based pipelines. In the case of Kubernetes, docker MUST be run externally so Docker swarm is used as it provides load balancing. Whilst the XNAT team work on replacing the Container service on Docker Swarm with a Kubernetes based Container service, Docker swarm is the most appropriate stop gap option.
Prerequisites
You will require the Docker API endpoint opened remotely so that XNAT can access and send pipeline jobs to it. For security, this should be done via HTTPS (not HTTP). Standard port is TCP 2376. With Docker Swarm enabled you can send jobs to any of the manager or worker nodes and it will automatically internally load balance. I chose to use the Manager node’s IP and pointed DNS to it. You should lock access to port 2376 to the Kubernetes XNAT subnets only using firewalls or Security Group settings. You can also use an external Load balancer with certificates which maybe preferred. If the certificates are not provided by a known CA, you will need to add the certificates (server, CA and client) to your XNAT container build so choosing a proper certificate from a known CA will make your life easier. If you do use self signed certificates, you will need create a folder, add the certificates and then specify that folder in the XNAT GUI > Administer > Plugin Settings > Container Server Setup > Edit Host Name. In our example case:
Certificate Path: /usr/local/tomcat/certs
Access from the Docker Swarm to the XNAT shared filesystem - at a minimum Archive and build. The AIS Helm chart doesn’t have /data/xnat/build setup by default but without this Docker Swarm can’t write the temporaray files it needs and fails.
Setup DNS and external certificates
Whether you will need to create self signed certificates or public CA verified ones, you will need a fully qualified domain name to create them against. I suggest you set an A record to point to the Manager node IP address, or a Load Balancer which points to all nodes. Then create the certificates against your FQDN - e.g. swarm.example.com.
Allow remote access to Docker API endpoint on TCP 2376
To enable docker to listen on port 2376 edit the service file or create /etc/docker/daemon.json.
We will edit the docker service file. Remember to specify whatever certificates you will be using in here. They will be pointing to your FQDN - in our case above, swarm.example.com.
Repeat on all nodes. Docker Swarm is now listening remotely on TCP 2376.
Secure access to TCP port 2376
Add a firewall rule to only allow access to TCP port 2376 from the Kubernetes subnets.
Ensure Docker Swarm nodes have access to the XNAT shared filesystem
Without access to the Archive shared filesystem Docker cannot run any pipeline conversions. This seems pretty obvious. Less obvious however is that the XNAT Docker Swarm requires access to the Build shared filesystem to run temporary jobs before writing back to Archive upon completion. This presents a problem as the AIS Helm Chart does not come with a persistent volume for the Build directory, so we need to create one. Create a volume outside the Helm Chart and then present it in your values file. In this example I created a custom class. Make sure accessMode is ReadWriteMany so Docker Swarm nodes can access.
You would need to create the custom-class storageclass and apply it first or the volume won’t be created. In this case, create a file - storageclass.yaml and add the followinng contents:
As you can see, the build directory is now a mounted volume. You are now ready to mount the volumes on the Docker swarm nodes.
Depending how you presented your shared filesystem, just create the directories on the Docker swarm nodes and manager (if the manager is also a worker), add to /etc/fstab and mount the volumes. To make your life easier use the same file structure for the mounts - i.e build volume mounted in /data/xnat/build and archive volume mounted in /data/xnat/archive. If you don’t do this you will need to specify the Docker swarm mounted XNAT directories in the XNAT GUI.
In the XNAT GUI, go to Administer > Plugin Settings > Container Server Setup and under Docker Server setup select > New Container host. In our above example, for host name you would select swarm.example.com, URL would be https://swarm.example.com:2376 and certificate path would be /usr/local/tomcat/certs. As previously mentioned, it is desirable to have public CA and certificates to avoid the needs for specifying certificates at all here. Select Swarm Mode to “ON”.
You will need to select Path Translation if you DIDN’T mount the Docker swarm XNAT directories in the same place. The other options are optional.
Once applied make sure that Status is “Up”.
The Image hosts section should also now have a status of Up.
You can now start adding your Images & Commands in the Administer > Plugin Settings > Images & Commands section.
Troubleshooting
If you have configured docker swarm to listen on port 2376 but status says down, firstly check you can telnet or netcat to the port first locally, then remotely. From one of the nodes:
nc -zv 127.0.0.1 2376
or
telnet 127.0.0.1 2376
If you can, try remotely from a location that has firewall ingress access. In our example previously, try:
Make sure the correct ports are open and accessible on the Docker swarm manager:
The network ports required for a Docker Swarm to function correctly are: TCP port 2376 for secure Docker client communication. This port is required for Docker Machine to work. Docker Machine is used to orchestrate Docker hosts. TCP port 2377. This port is used for communication between the nodes of a Docker Swarm or cluster. It only needs to be opened on manager nodes. TCP and UDP port 7946 for communication among nodes (container network discovery). UDP port 4789 for overlay network traffic (container ingress networking).
Make sure docker service is started on all docker swarm nodes.
If Status is set to Up and the container automations are failing, confirm the archive AND build shared filesystems are properly mounted on all servers - XNAT and Docker swarm. A Failed (Rejected) status for a pipeline is likely due to this error.
In this case, as a service can’t be created you won’t have enough time to see the service logs with the usual:
docker service ls
command followed by looking at the service in question, so stop the docker service on the Docker swarm node and start in the foreground, using our service example above:
Connecting AIS XNAT Helm Deployment to an External Postgresql Database
By default, the AIS XNAT Helm Deployment creates a Postgresql database in a separate pod to be run locally on the cluster. If the deployment is destroyed the data in the database is lost. This is fine for testing purposes but unsuitable for a production environment. Luckily a mechanism was put into the Helm template to allow connecting to an External Postgresql Database.
Updating Helm charts values files to point to an external Database
Needs to be changed to false to disable creation of the Postgresql pod and create an external database connection.
The other details are relatively straightforward - Generally you would only specify either: postgresqlExternalName or postgresqlExternalIPs postgresqlPassword will be your database user password.
An example configuration using a sample AWS RDS instance would look like this:
Change to match your environment as with the other values.yaml.
You should now be able to connect your XNAT application Kubernetes deployment to your external Postgresql DB to provide a suitable environment for production.
For more details about deployment have a look at the README.md here: https://github.com/Australian-Imaging-Service/charts/tree/main/releases/xnat
Creating an encrypted connection to an external Postgresql Database
The database connection string for XNAT is found in the XNAT home directory - usually /data/xnat/home/config/xnat-conf.properties
By default the connection is unencrypted. If you wish to encrypt this connection you must append to the end of the Database connection string.
Do not require validation of Certificate Authority
The last option is useful as otherwise you will need to import the CA cert into your Java keystone on the docker container. This means updating and rebuilding the XNAT docker image before being deployed to the Kubernetes Pod and this can be impractical.
Complete string would look like this ( all on one line): datasource.url=jdbc:postgresql://xnat-postgresql/yourdatabase?ssl=true&sslmode=require&sslfactory=org.postgresql.ssl.NonValidatingFactory
Update your Helm Configuration:
Update the following line in charts/releases/xnat/charts/xnat-web/templates/secrets.yaml from:
It should be noted that the Database you are connecting to needs to be encrypted in the first place for this to be successful.
This is outside the scope of this document.
3.3.5 - Logging With EFK
EFK centralized logging collecting and monitoring
For AIS deployment, we use EFK stack on Kubernetes for log aggregation, monitoring and anyalysis. EFK is a suite of 3 different tools combining Elasticsearch, Fluentd and Kibana.
Elasticsearch nodes form a cluster as the core. You can run single node Elasticsearch. However, a high availablity Elasticsearch cluster requires 3 master nodes as a minimum. If there is one node fails, the Elasticsearch cluster still functions and can self heal.
Kibana instance is used as the visualisation tool for users to interact with the Elasticsearch cluster.
Fluentd is used as the log collector.
In the following guide, we leverage Elastic and Fluentd’s official Helm charts before using Kustomize to customize other required K8s resources.
Creating a new namespace for EFK
$ kubectl create ns efk
Add official Helm repos
For both Elasticsearch and Kibana:
$ helm repo add elastic https://helm.elastic.co
As of this writing, the latest helm repo supports Elasticsearch 7.17.3. It doesn’t work with the latest Elasticsearch v8.3 yet.
Adhere to the Elasticsearch security principles, all traffic between nodes in Elasticsearch cluster and traffic between the clients to the cluster needs to be encrypted. You use self signed certicate in this guide.
Generating self signed CA and certificates
Below we use elasticsearch-certutil to generate password protected self signed CA and certificates, then use openssl tool to convert it to pem formatted certificate
Convert the generated CA and certificates to based64 encoded format. These will be used to create the secrets in K8s. Alternatively, you can use kubectl to create the secrets directly
Add configuration file elasticsearch.yaml. Enable transport TLS for internode encrypted communication and HTTP TLS for client encryped communication. Previously generated certificates are used, they are passed in from the mounted Secrets
Create storageclass.yaml as referenced above. Below is the example when using AWS EFS as the persistent storage. You can adjust to suit your storage infrastructure.
Add below kibana.yml configuration file that enables Kinana to talk to Elasticsearch on encrypted connection.
For xpack.security.encryptionKey, you can use any text string that is at least 32 characters. Certificates are mounted from the secret resource
apiVersion: v1
data:
# use base64 format of values of elasticsearch's elastic-certificate.pem and elastic-ca-cert.pem
elastic-certificate.pem: Changeme
elastic-ca-cert.pem: Changme
kind: Secret
metadata:
name: elastic-certificates-pem
namespace: efk
type: Opaque
---
apiVersion: v1
data:
# use base64 format of the value you use for xpack.security.encryptionKey
encryptionkey: Changeme
kind: Secret
metadata:
name: kibana
namespace: efk
type: Opaque
Optional: create an Ingress resource to point to the Kibana serivce
Install/update the Kibana chart
Change to where your Kustomize directory for Kibana and run
Fluentd is created using Daemonset which ensure a Fluentd pod is created on each worker node. Wait till you will see the fluentd pods are in “running” status
$ kubectl get po -l app.kubernetes.io/name=fluentd -n efk
3.3.6 - PostgreSQL Database Tuning
XNAT Database Tuning Settings for PostgreSQL
If XNAT is performing poorly, such as very long delays when adding a Subjects
tab, it may be due to the small default Postgres memory configuration.
To change the Postgres memory configuration to better match the available
system memory, add/edit the following settings in
/etc/postgresql/10/opex/postgresql.conf
Tool selection has been chosen with a security oriented focus but enabling collaboration and sharing of site specific configurations, experiences and recommendations.
Security
A layered security approach with mechanisms to provide access at granular levels either through Access Control Lists (ACLs) or encryption
Automated deployment
Allow use of Continuous Delivery (CD) pipelines
Incorporate automated testing principals, such as Canary deployments
Encryption of secrets to allow configuration to be securely placed in version control.
SOPS allows full file encryption much like many other tools, however, individual values within certain files can be selectively encrypted. This allows the majority of the file that does not pose a site specific security risk to be available for review and sharing amongst Federated support teams. This should also comply with most security team requirements (please ensure this is the case)
Can utilise GnuPG keys for encryption but also has the ability to incorporate more Corporate type Key Management Services (KMS) and role based groups (such as AWS AIM accounts)
Git enhancement that utilises pattern matching to help prevent sensitive information being submitted to version control by accident.
Warning
Does not replace diligence but can help safe guard against mistakes.
3.3.8 -
Operational recommendations
The /docs/_operational folder is a dump directory for any documentation related to the day-to-day runnings of AIS released services. This includes, but is not limited to, operational tasks such as:
Administration tasks
Automation
Release management
Backup and disaster recovery
Jekyll is used to render these documents and any MarkDown files with the appropriate FrontMatter tags will appear in the Operational drop-down menu item.